本文在钉钉文档完成,所以导出为md格式有一些排版问题,另附PDF文件,建议阅读PDF文件。
Weight
The LLMs we commonly use today are almost exclusively built on the Decoder-only architecture.
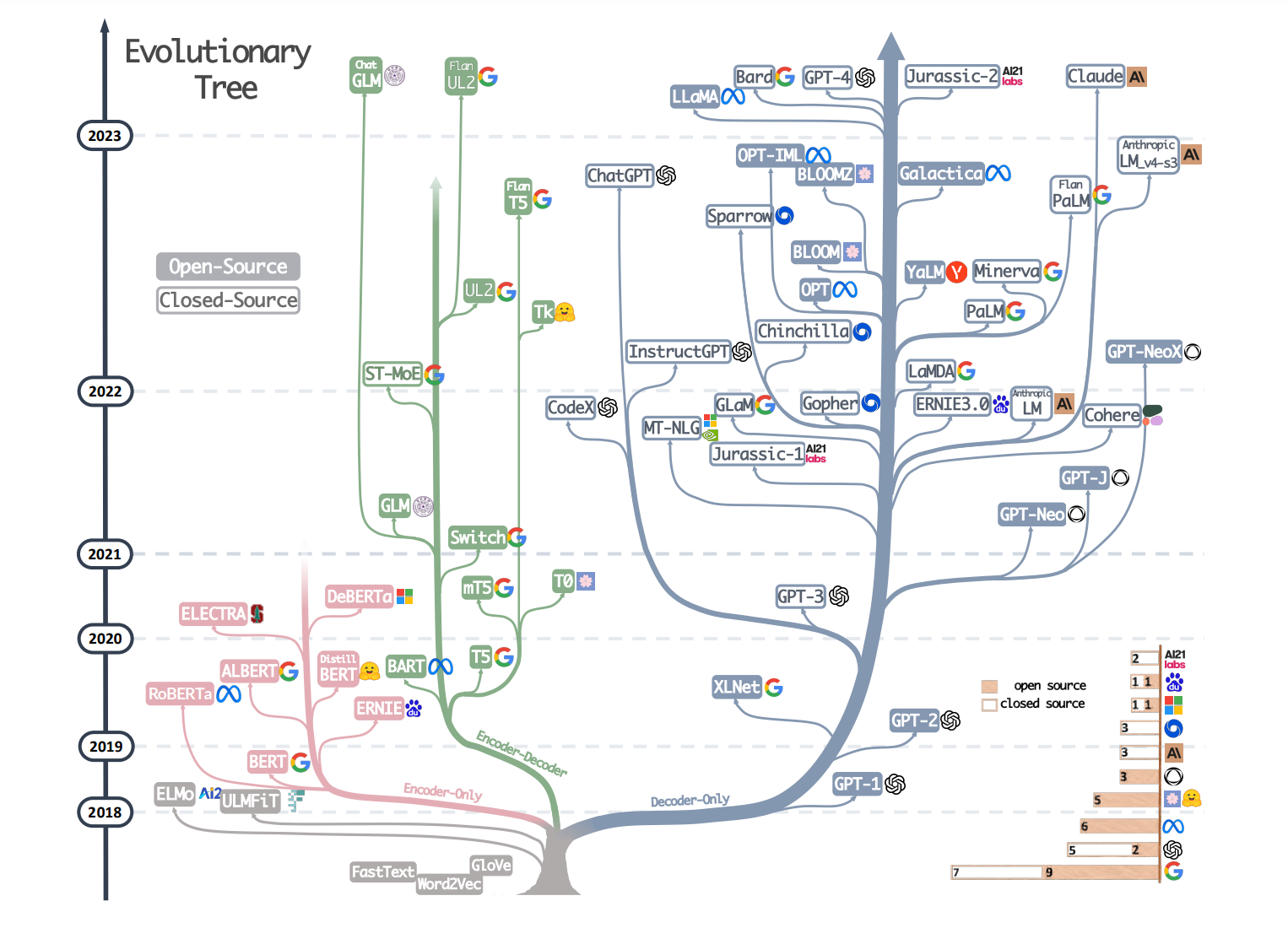
Fig.1.The evolutionary tree of modern LLMs[1]
The Transformer block in the Decoder-only architecture is illustrated in the following figure.
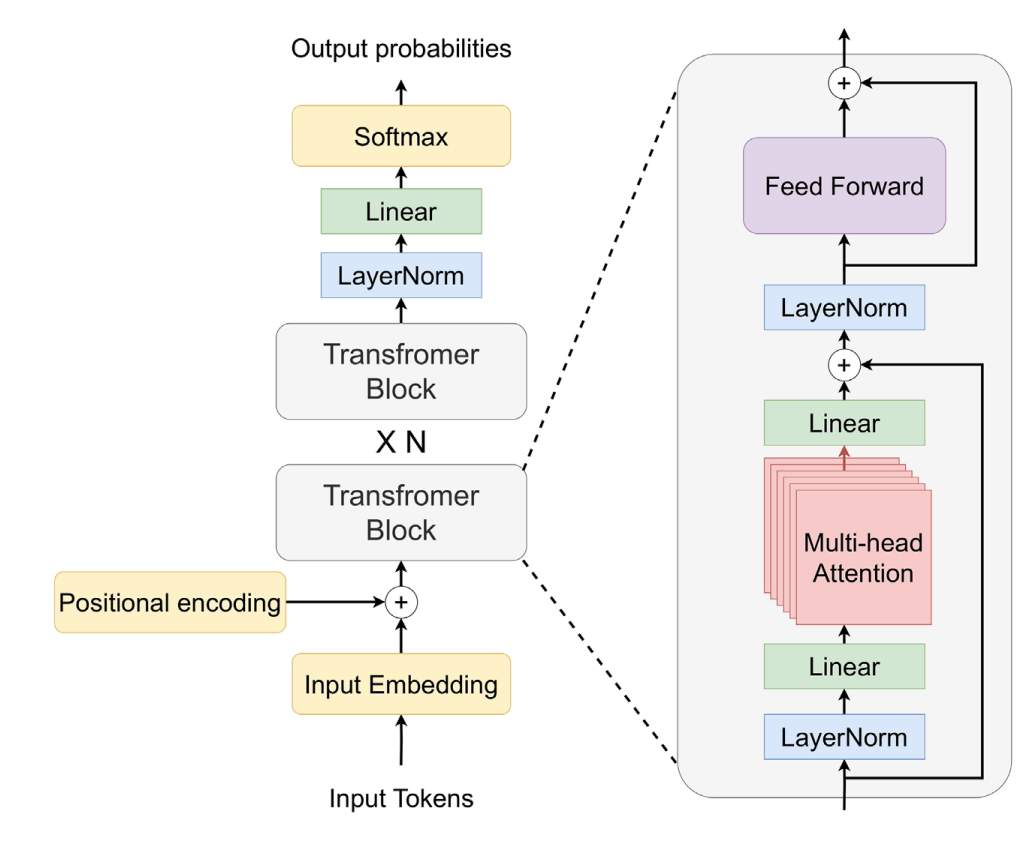
Fig.2.Decoder-only Transformer architecture[2]
First, let’s calculate the parameters of the attention module. Its structure is as follows, involving four matrices: Q, K, V for the dot-product attention and the O matrix for the linear transformation after dot-product attention.
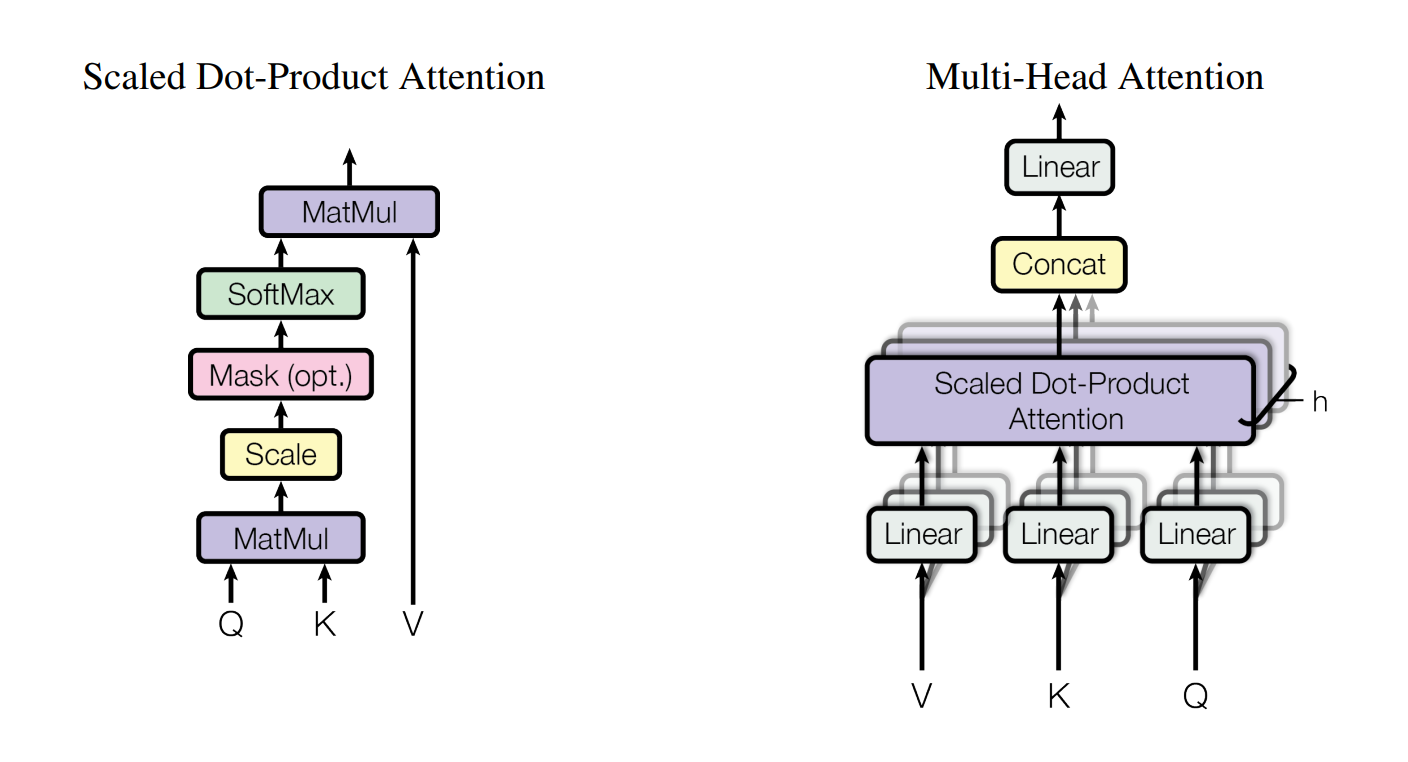
Fig.3. Multi-Head Attention[3]
Denote the hidden dimension of the transformer by $h_1$.Given the weight matrices of a transformer layer by $w_q,w_k.w_v,w_o \in {R}^{h_1 \times h_1}$.The size of the multi-head attention mechanism module is ${n\_bytes} \times 4 \times {h_1}^2$,where ${n\_bytes}$indicate the number of bytes per param; for float32s, this is 4, for float16s, this is 2, etc.
The second part is the FFN (Feed Forward Network), which is essentially composed of two linear layers:
$\operatorname{FFN}(x)=f_{relu} \left(0, x W_1+b_1\right) W_2+b_2$
The hidden dimension of the second MLP layer by $h_2$(typically four times the size of $h_1$) . So,the size of FFN is ${n\_bytes} \times2h_1h_2$.
Denote the total number of transformer layers by $l$,the total weight of a LLM is ${n\_bytes} \times \left(4 {h_1}^2+ 2h_1h_2\right)$
(We ignore the embedding layer(s), which is relatively small)
Flops counting
This part is primarily referenced from [6].
How many flops in a matmul?
The computation for a matrix-vector multiplication is $2mn$for $A\in \mathbb{R}^{m \times n} ,b \in \mathbb{R}^n$.A matrix-matrix is $2mnp$ for $A\in \mathbb{R}^{m \times n} ,B \in \mathbb{R}^{n \times p}$.
If we consider only the calculation for K and V , the total memory required is${n\_bytes} \times 2 l {h_1}^2 + n_{token}\times h_1$,and the flops are $n_{token} \times 2 \times 2 l {h_1}^2$.
Therefore, if we use half-precision (float16) and perform inference using an A100 GPU( its FP16 Tensor Core performance is 312 TFLOPs, and its bandwidth is 1555 GB/s. The speed difference between the two is approximately 208 times! ).We assume (correctly, this has been very well optimised) that we can start the computations while we load the weights. This means that if we’re going to compute KV for one token, it’ll take the same amount of time to compute for up to 208 tokens(We ignore the $n_{token}\times h_1$, which is relatively small).
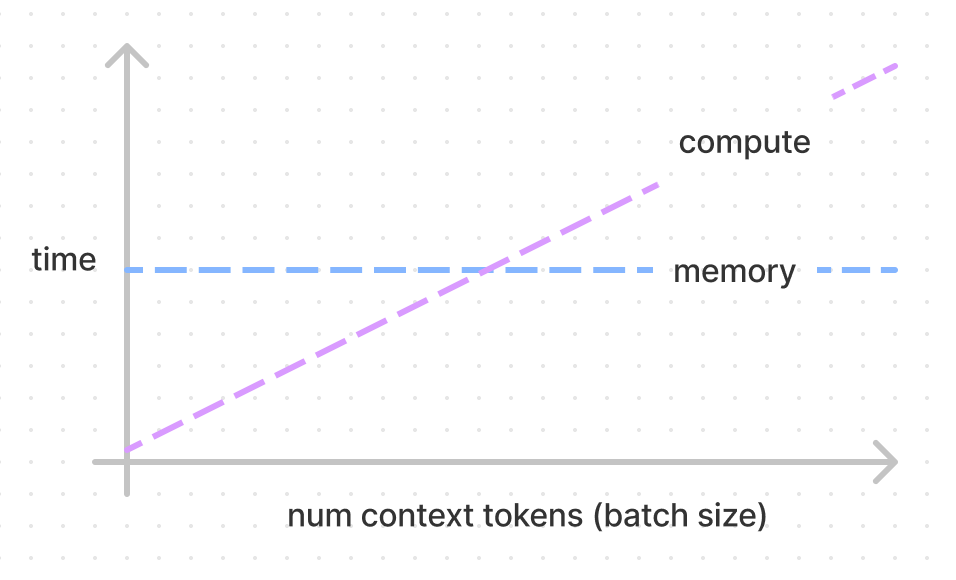
Fig.4.The number of tokens leads to different bounds[6]
KV Cache
Because the decoder works in an auto-regressive fashion,and will inference token by token.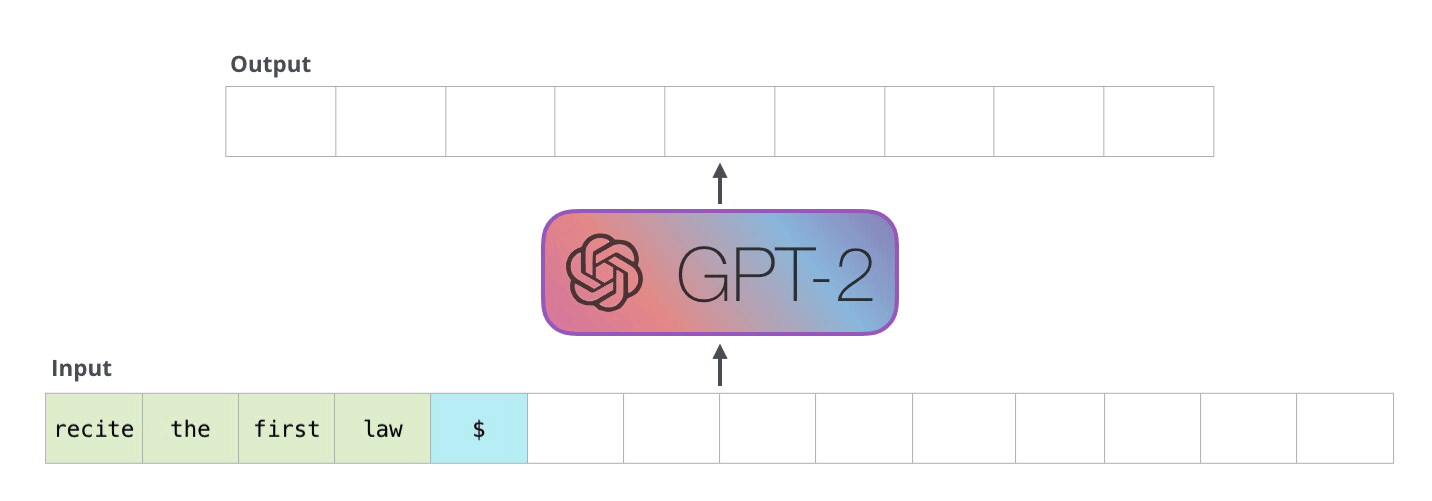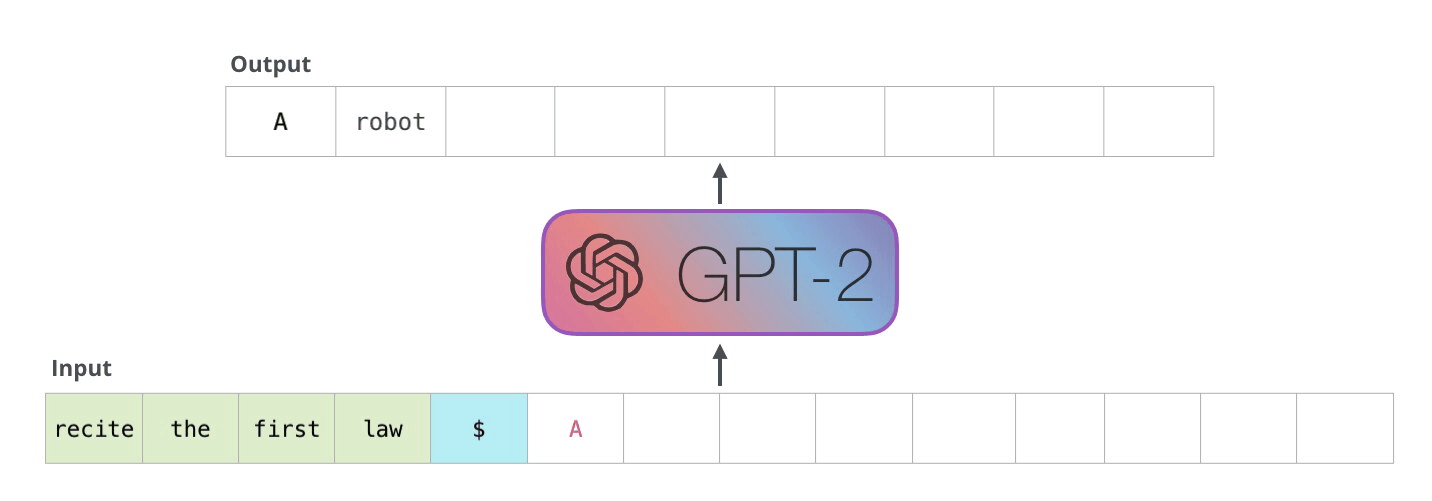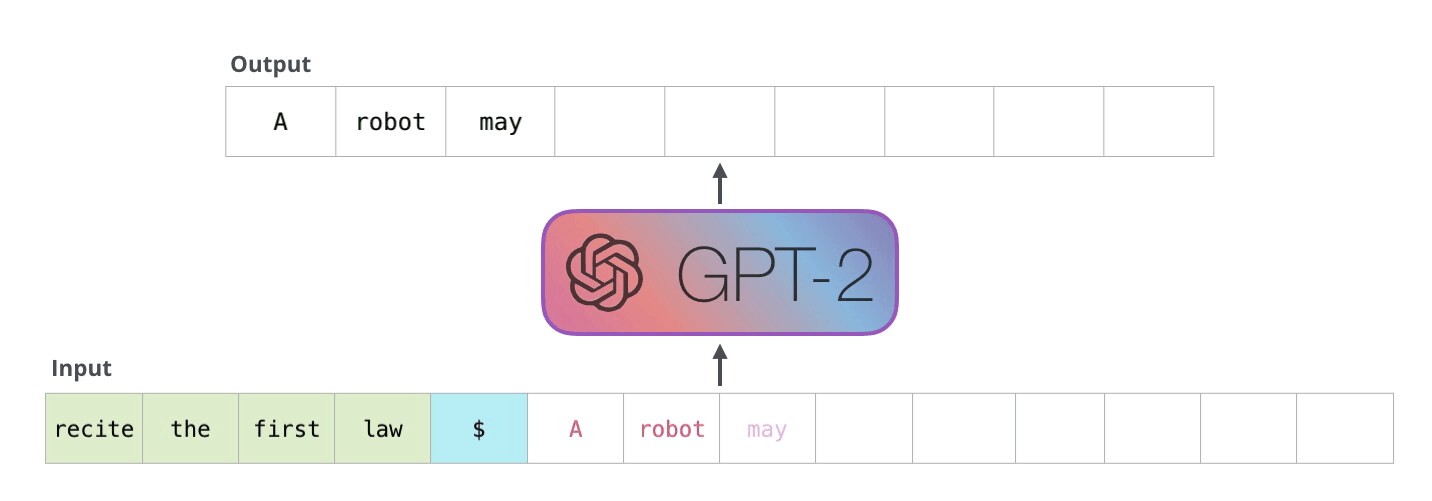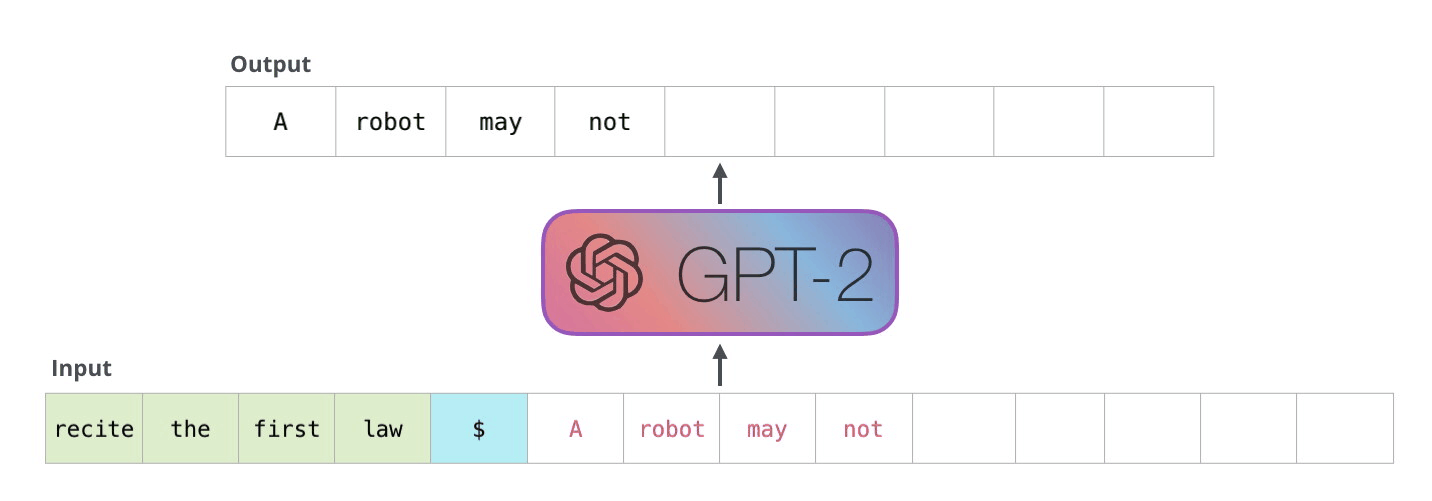
Fig.5.Auto-regreessive[4]
This autoregressive behavior repeats some operations and redundantly computes the K and V values generated by earlier tokens:
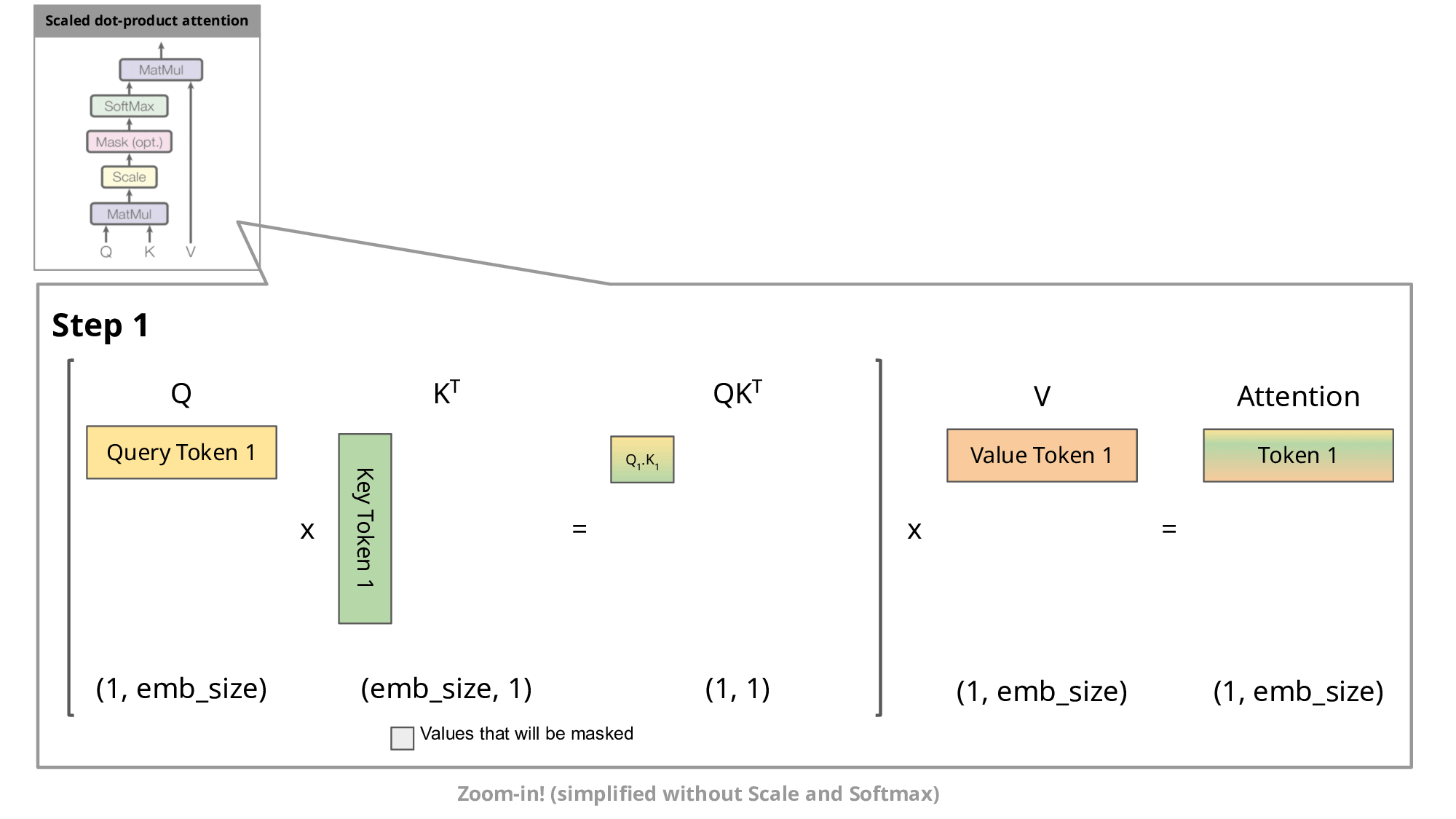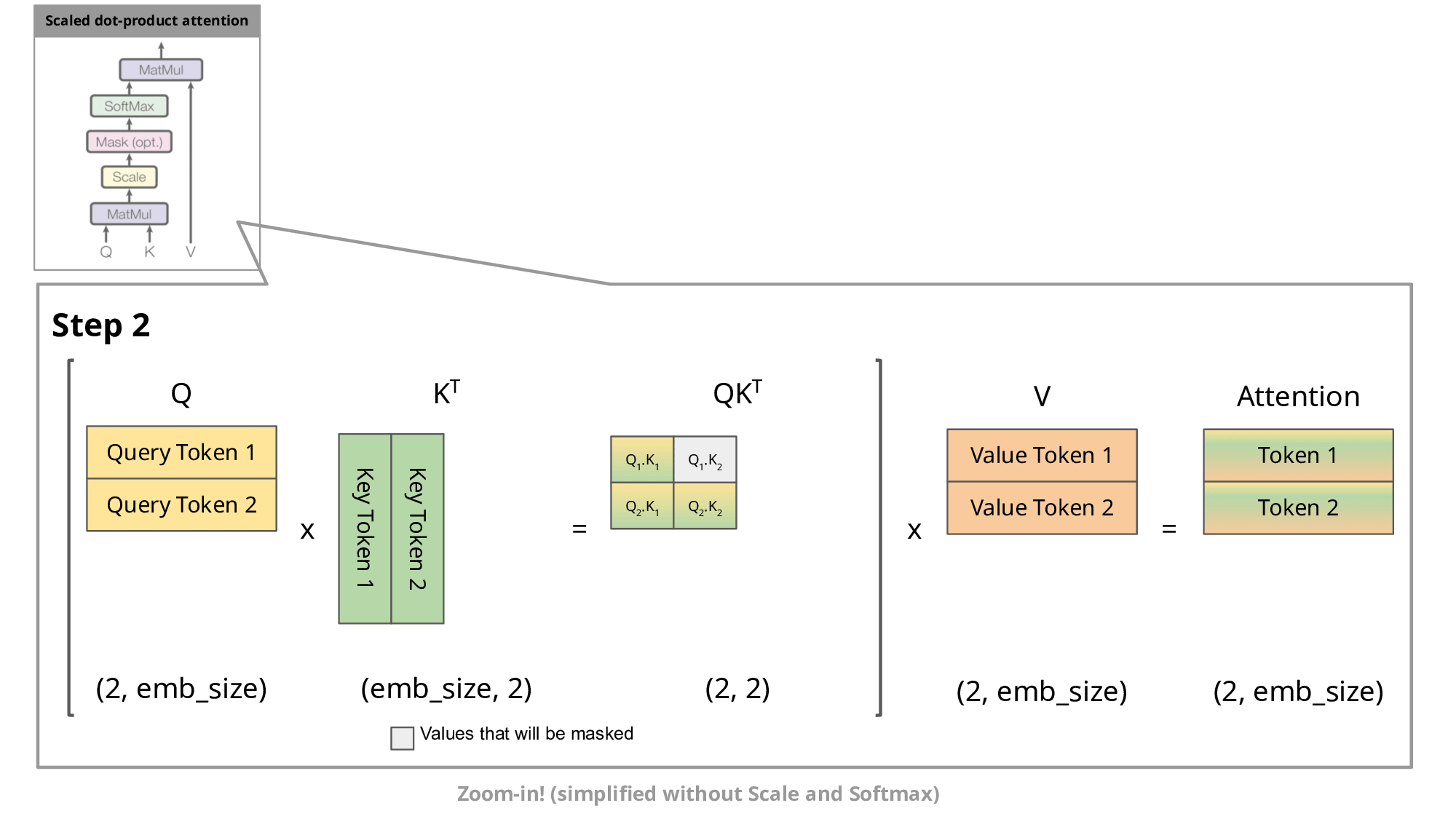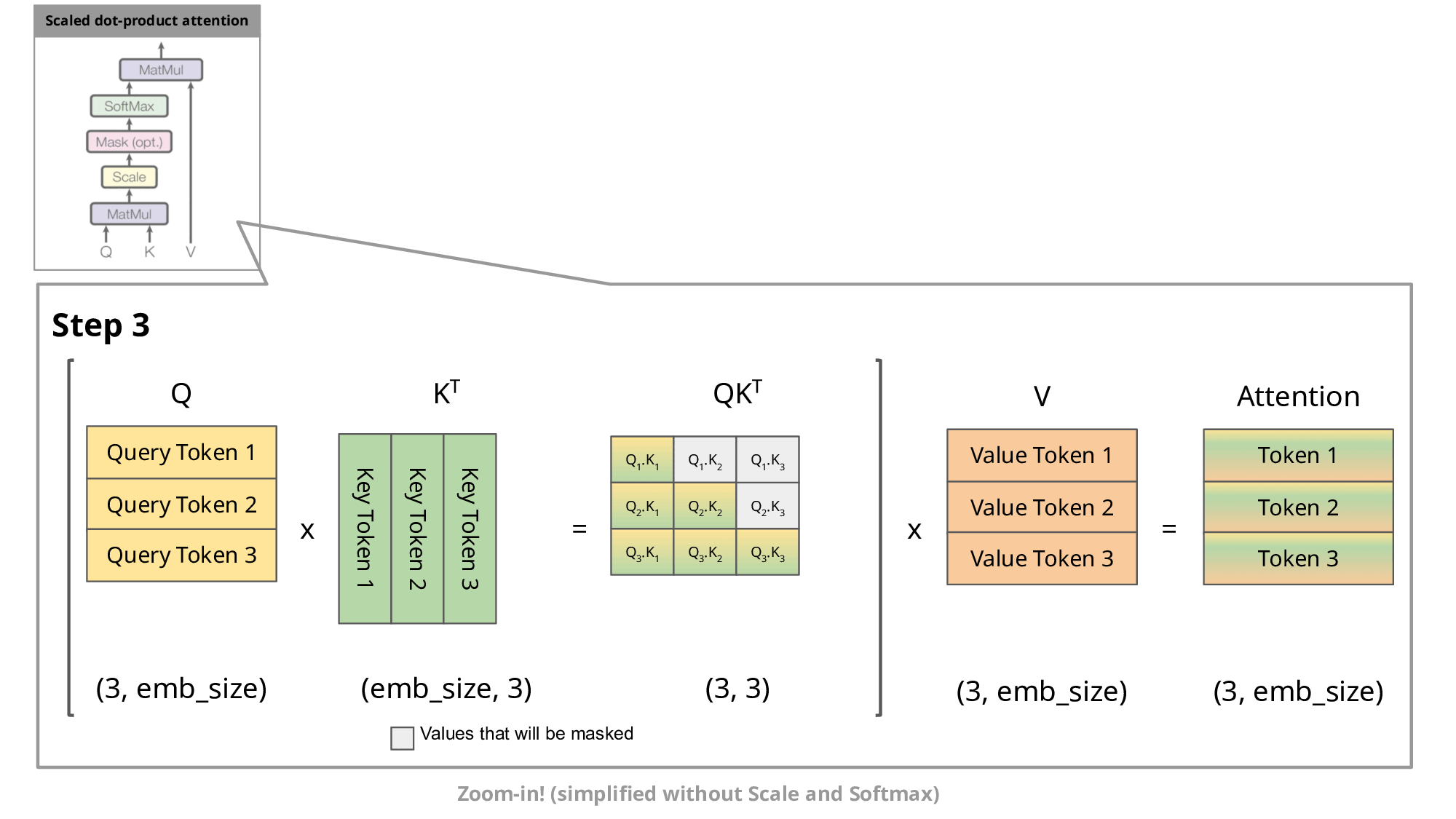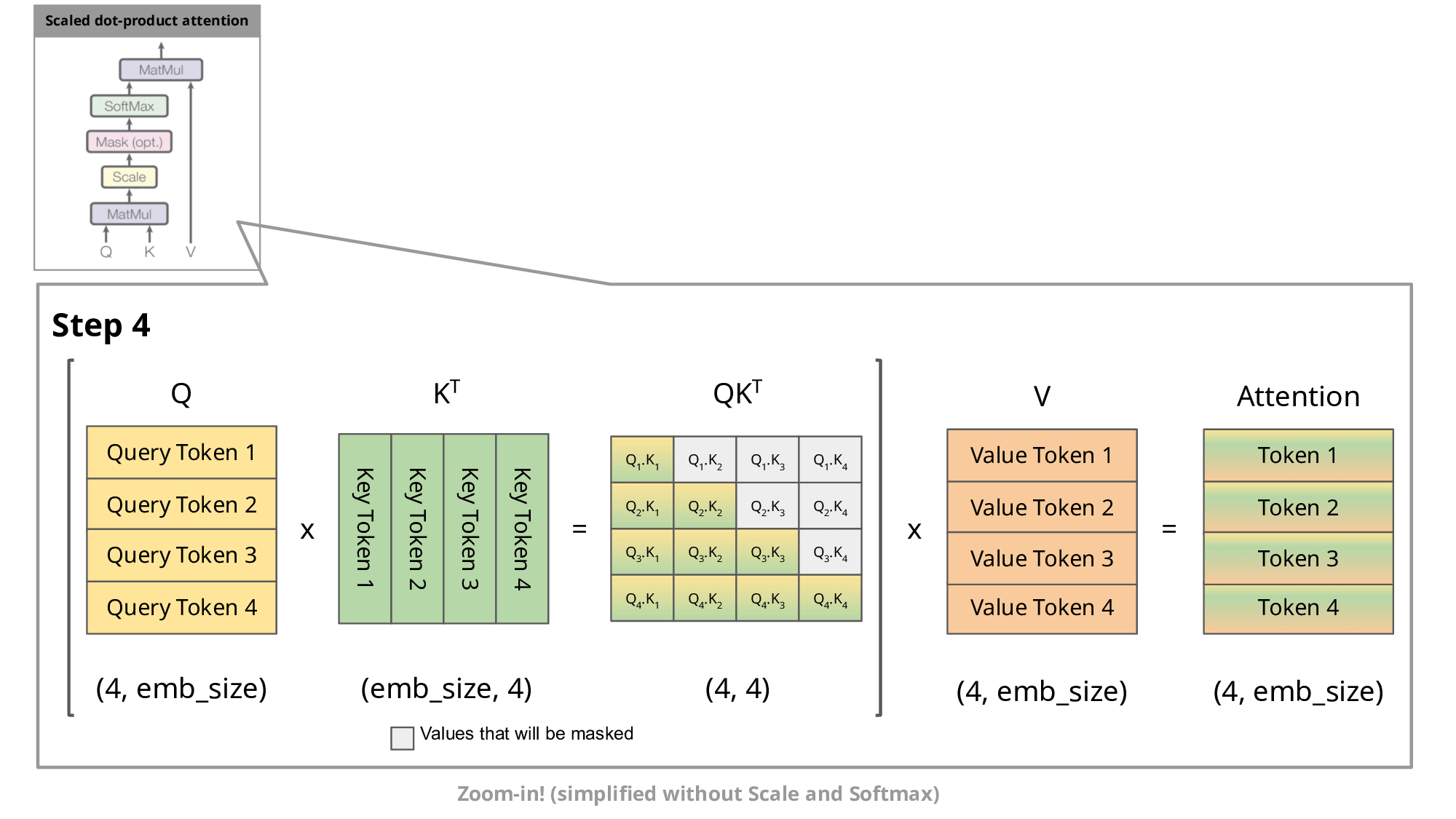
Fig.6.Step-by-step visualization of the scaled dot-product attention in the decoder[4]
Since the decoder is causal (i.e., the attention of a token only depends on its preceding tokens), at each generation step we are recalculating the same previous token attention, when we actually just want to calculate the attention for the new token.
This is where KV comes into play. By caching the previous Keys and Values, we can focus on only calculating the attention for the new token.
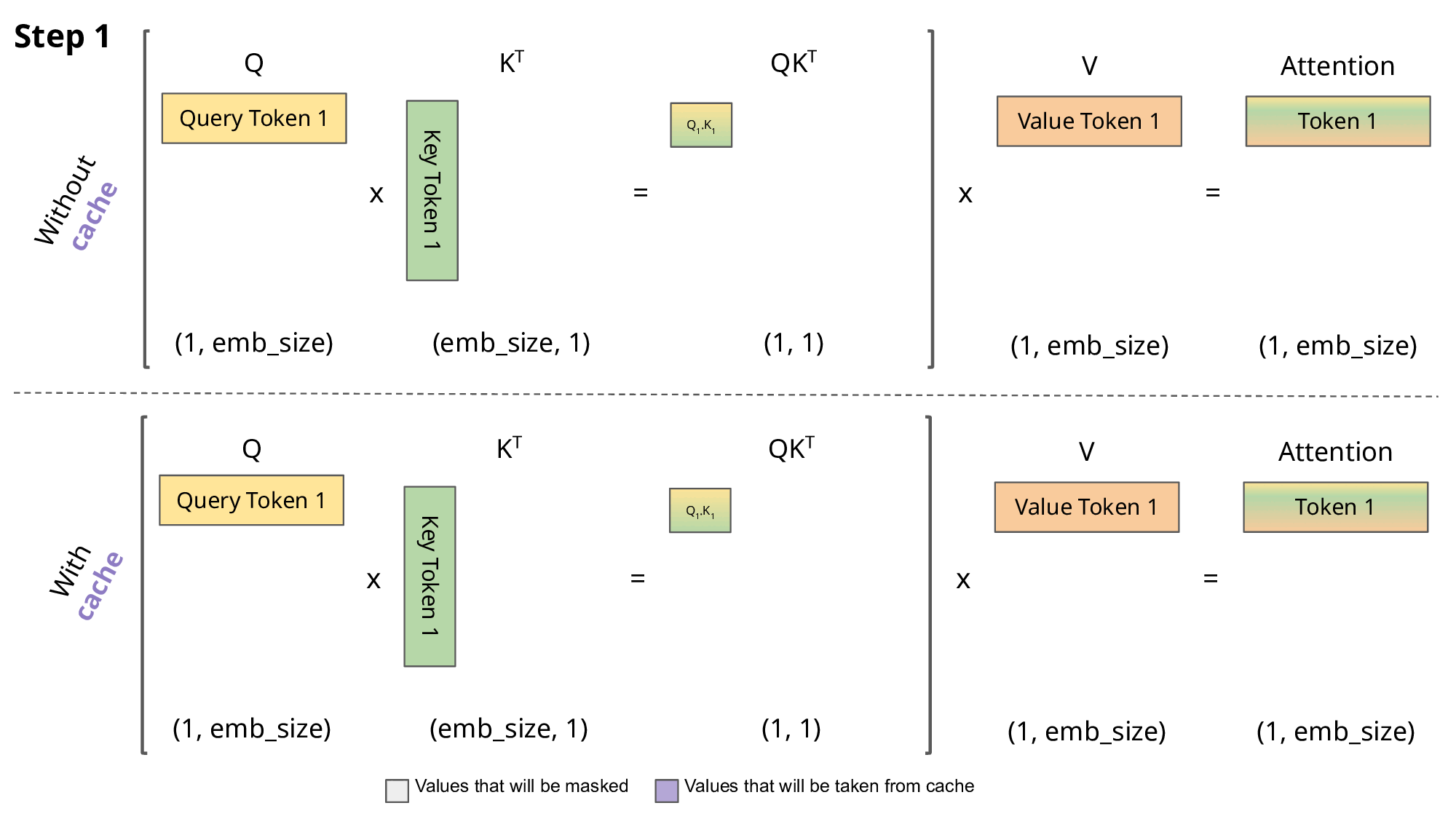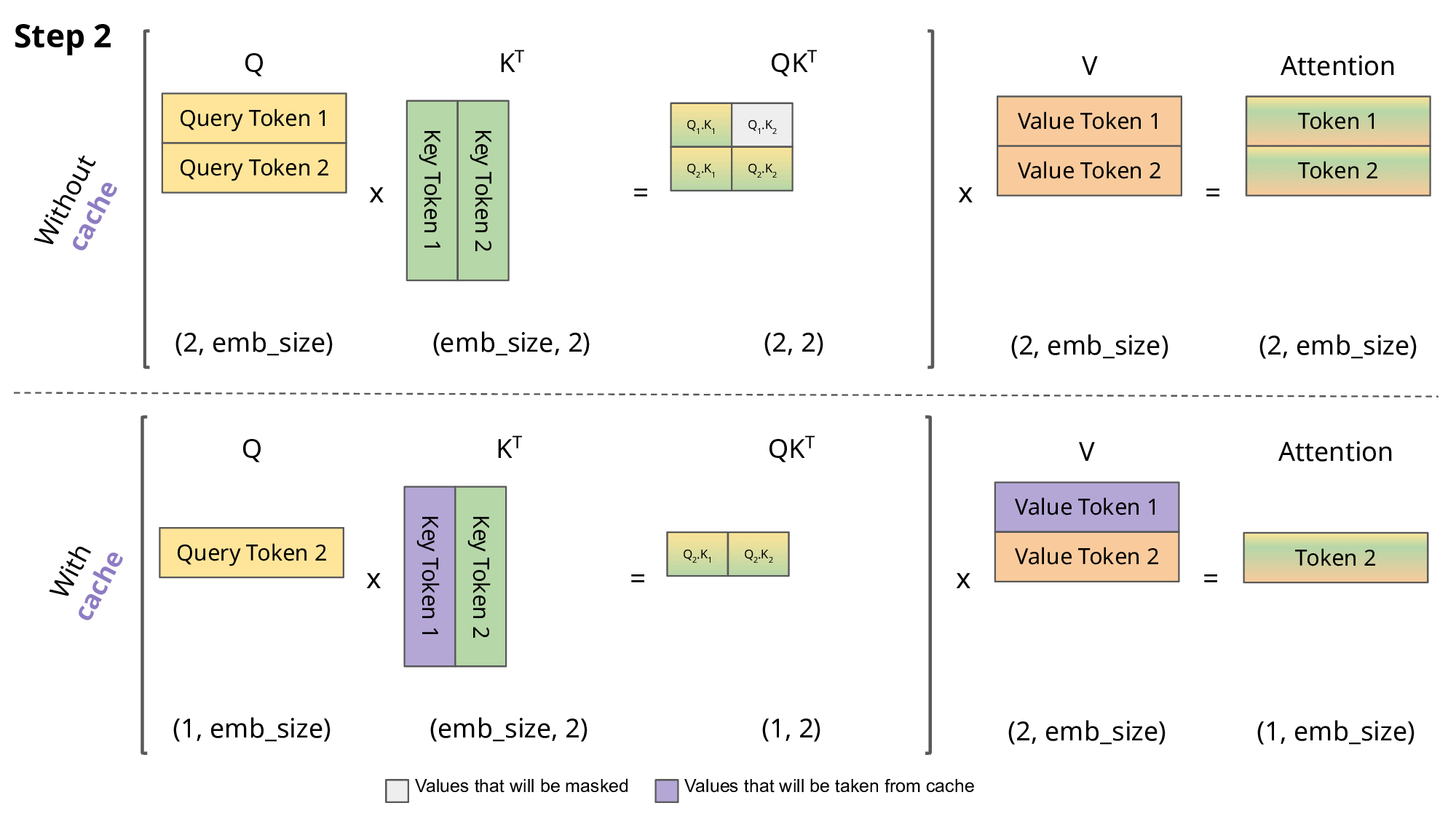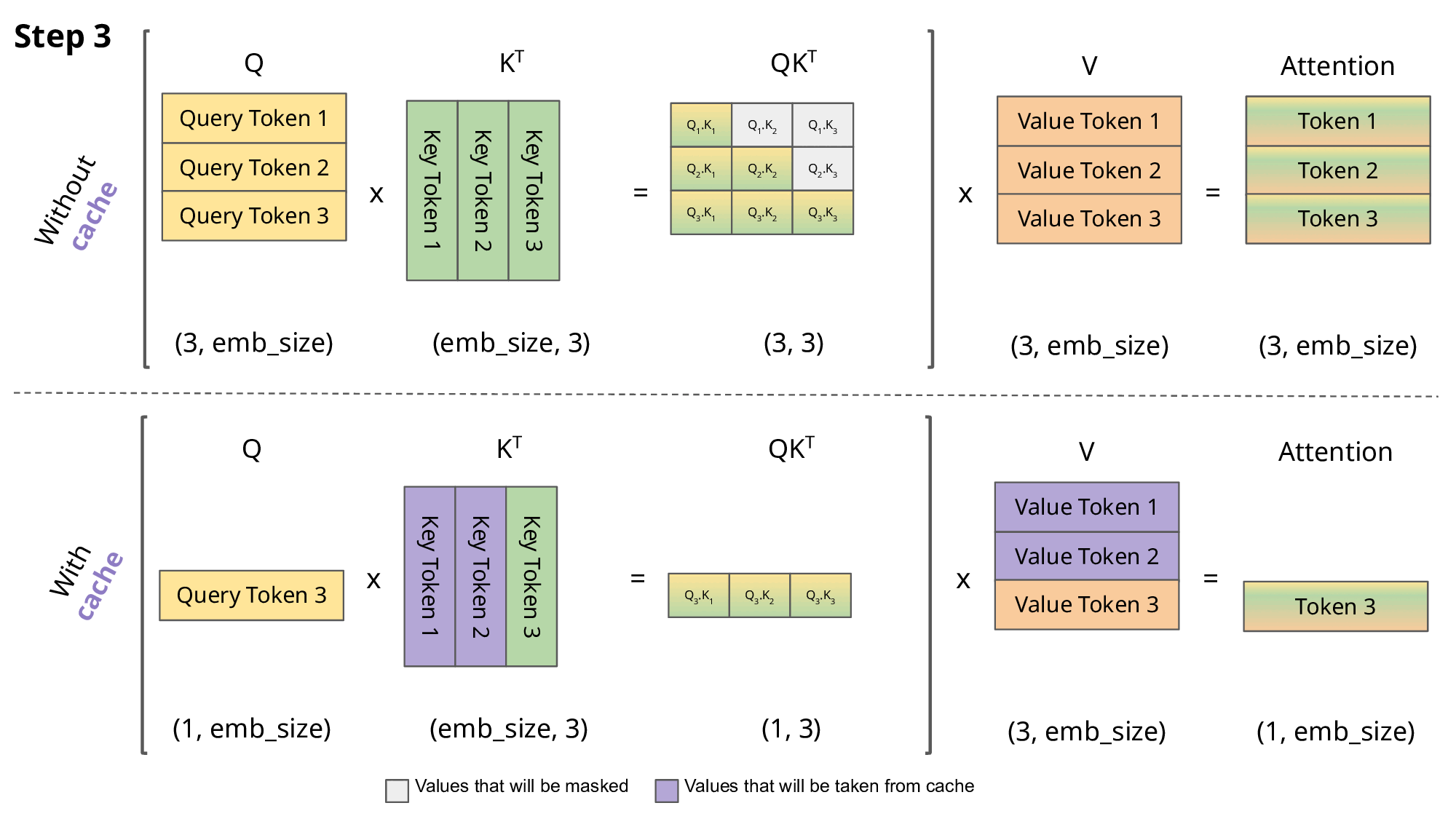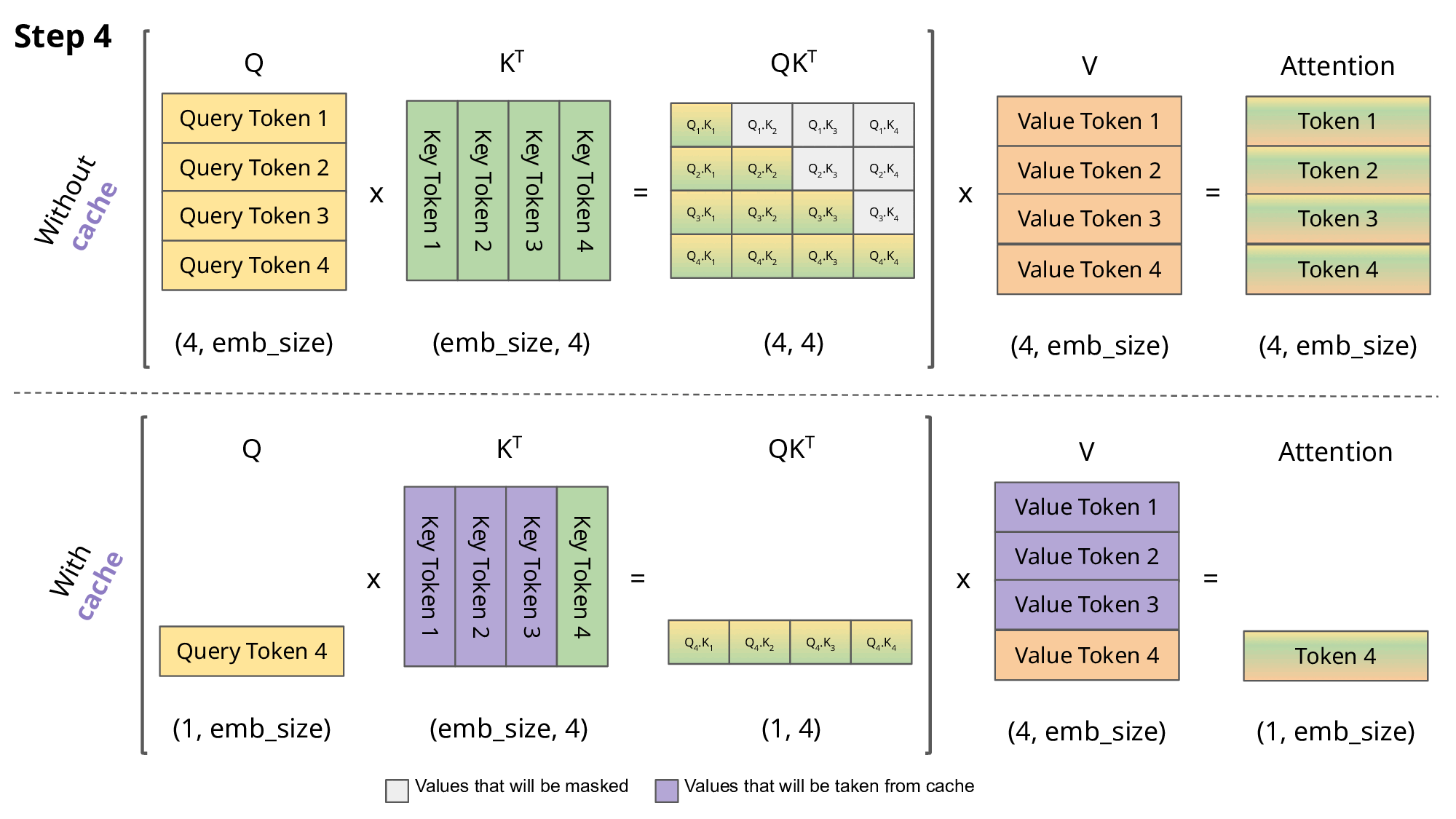
Fig.7.Comparison of scaled dot-product attention with and without KV caching[4]
Why is this optimization important? As seen in the picture above, the matrices obtained with KV caching are way smaller, which leads to faster matrix multiplications. The only downside is that it needs more RAM to cache the Key and Value states.
So let’s calculate the memory of KV cache.Denote the the input sequence( prompt) length by $s$, the output sequence length by $n$,and the batch size by $b$,The total number of bytes to store the KV cache in peak is ${n\_bytes} \times2 \times bl{h_1} \left(s+n\right)$.
In the setting of FlexGen[5], the OPT-175B model ($l$ = 96,$h_1$ = 12288, $h_2$ = 49152) takes 325 GB. With a batch size of $b$ = 512, an input sequence length $s$ = 512, and an output sequence length of $n$ = 32, the total memory required to store the KV cache is 1.2 TB, which is 3.8× the model weights, making the KV cache a new bottleneck of large-batch high-throughput inference.
Memory-bound
This part is primarily referenced from [7].
In addition to the analysis above, we also face a more severe memory-bound issue, especially with operations like Softmax.
The operations in a Transformer block can be categorized into three types[7]:
Tensor Contractions: These are matrix-matrix multiplications (MMMs), batched MMMs, and in principle could include arbitrary tensor contractions.
**Statistical Normalizations:**These are operators such as softmax and layer normalization. These are less computeintensive than tensor contractions, and involve one or more reduction operation, the result of which is then applied via a map. This compute pattern means that data layout and vectorization is important for operator performance.
Element-wise Operators: These are the remaining operators: biases, dropout, activations, and residual connections.
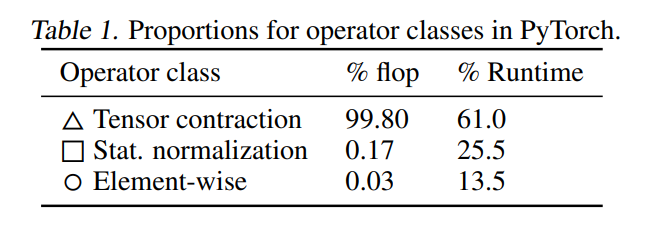
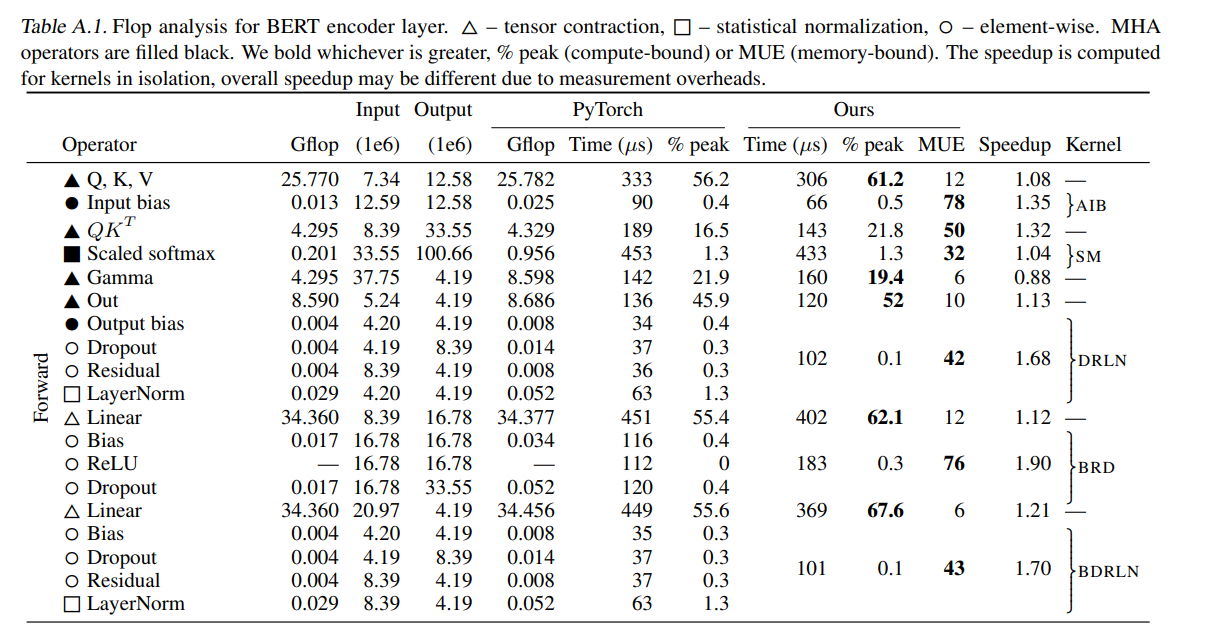
We can observe that softmax occupies most of the computation time, and the Memory Usage Efficiency (MUE) value indicates that it is memory-bound.
There are many approaches aimed at optimizing memory to enhance the performance of large models, such as FlashAttention[8],vLLM[9].
-
Yang J, Jin H, Tang R, et al. Harnessing the power of llms in practice: A survey on chatgpt and beyond[J]. arXiv preprint arXiv:2304.13712, 2023.
-
Chalvatzaki G, Younes A, Nandha D, et al. Learning to reason over scene graphs: a case study of finetuning GPT-2 into a robot language model for grounded task planning[J]. Frontiers in Robotics and AI, 2023, 10.
-
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
-
João Lages. Transformers KV Caching Explained. https://medium.com/@joaolages/kv-caching-explained-276520203249
-
Sheng Y, Zheng L, Yuan B, et al. High-throughput generative inference of large language models with a single gpu[J]. arXiv preprint arXiv:2303.06865, 2023.
-
Chen, Carol. Transformer Inference Arithmetic, https://kipp.ly/blog/transformer-inference-arithmetic/
-
Ivanov A, Dryden N, Ben-Nun T, et al. Data movement is all you need: A case study on optimizing transformers[J]. Proceedings of Machine Learning and Systems, 2021, 3: 711-732.
-
Dao T, Fu D, Ermon S, et al. Flashattention: Fast and memory-efficient exact attention with io-awareness[J]. Advances in Neural Information Processing Systems, 2022, 35: 16344-16359.
-
Kwon W, Li Z, Zhuang S, et al. Efficient memory management for large language model serving with pagedattention[J]. arXiv preprint arXiv:2309.06180, 2023.